Note: I have rewritten this article to make it more straightforward, and also I have corrected a lot of grammatical errors.
With this article, I plan to explain the intuition behind the following “recursive” formula.

or

Let’s start by building a mental model, imagine that you have two baskets with you. Let’s call the first as  , has a capacity of
, has a capacity of 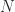 and is full. The second,
and is full. The second,  has a capacity
has a capacity  (for clarity,
(for clarity, 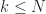 ) and empty. For simplicity, let’s assume that all items are distinct and distinguishable.
) and empty. For simplicity, let’s assume that all items are distinct and distinguishable.
The idea of choosing items from is nothing but counting the number of ways you can pick items from and put it in .
Another critical thing to note is that, while computing combinations, the order of how you choose those items is unimportant, the only thing that matters is what items you choose. Choosing items from is mathematically denoted as  and I shall be using this notation from now on.
and I shall be using this notation from now on.
One way to approach a problem recursively is to see if it makes sense to decrease the problem size by one and delegate the problem to someone else. Let’s do just that, and pick an item out of . Now you can either put it in or keep it aside. Each choice leads to interesting consequences:
Case 1: The item was placed in , so now has 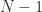 items in it, and you can only put
items in it, and you can only put 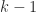 items in . So now you have to choose items from items or in other words
items in . So now you have to choose items from items or in other words 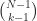 .
.
Case 2: The item was placed aside (not in ), consequently has items in it, but is still empty and you can still put items in it. This translates to you having to choose items from items or in other words 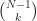 .
.
We can conclude that the number of ways of choosing items from is the sum of:
- Number of ways of choosing items from
- Number of ways of choosing items from .
Thus we have derived the recursive equation, .
Are we done? No, not yet. We still haven’t discussed another crucial thing when it comes to recursion, the base cases. Base cases are how the recursive formulae yield an outcome.
Q1) What is  ?
?
A: We have only one way of choosing all the items from and putting them into . Hence, we can also conclude that  is
is  .
.
Q2) What is  ?
?
A: We have choices, hence ways of choosing one item from items.
Let us make how we stop our recursion a bit smarter by considering the following case:
Q3) What is  ?
?
A: Choosing items out of is the same as not choosing 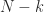 items out of . Hence, you have
items out of . Hence, you have 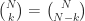 . You can derive some interesting results out of this, here are a few
. You can derive some interesting results out of this, here are a few
(call this
), what is the maximum subarray sum ending at position
(equivalently, what is
? The answer turns out to be relatively straightforward: either the maximum subarray sum ending at position
, where
is the element at index
 digits
digits 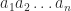 , then the number
, then the number 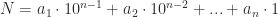
 and see what we get.
and see what we get.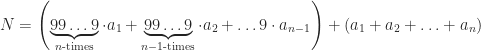
 . So a number
. So a number  which has
which has 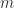 digits in it and all
digits in it and all 
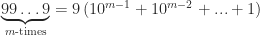
 . To delve a bit deeper into it, we first allocate an array of size
. To delve a bit deeper into it, we first allocate an array of size 
 , it gets re-sized to this number, instead of holding up space for all the
, it gets re-sized to this number, instead of holding up space for all the  times.
times. we get:
we get:
 . Such a guarantee/cost analysis is formally known as an amortized guarantee/analysis depending on the context.
. Such a guarantee/cost analysis is formally known as an amortized guarantee/analysis depending on the context.

